AWS + 쿠버네티스 환경에서의 로그 시스템 구축 전략

AWS 클라우드 환경 여러 서비스 서버들에 대한 로그중앙화 관리 아키텍처 설계
1 Description
AWS 클라우드 환경 내에 클라우드를 배포/운영하는 시스템들에 대해 로그 시스템을 중앙화하는 방법에 대한 아키텍처 설계를 진행한다.(구체적인 세부 설정 - 리소스 구성 스펙 및 운영상 편의를 위한 옵션 설정에 대한 설명은 제외)
2 Background
로그 분석 시스템에 있어 Elastic Search는 가장 대표적인 로그 분석 시스템이다.
가장 대표적인 구성으로 ELK를 많이 언급한다. ELK는 로그 시스템을 구축하기 위한 모듈의 조합으로 Data Shipper(아래 이미지에서는 beats가 대행) 역할 및 Data Parsing을 담당하는 Logstash, 데이터에 대한 저장/색인/조회 역할을 하는 Elastic Search, 사용자에게 UI를 제공하는 Kibana 조합이다.
3 Architecture
ELK 조합을 사용한다면 아래 그림과 같은 구조로 간단히 구성할 수 있다.
3.1 Basic
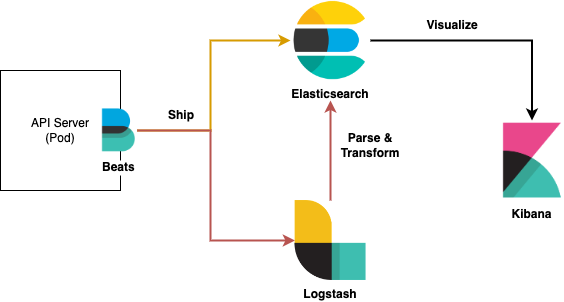
서버 인스턴스에서 파일에 로그를 생성하고, Data Shipper인 파일비트를 통해 로그를 전송한다. json으로 구성되어 있다면, ES(Elastic Search의 데이터 노드 적재)로 직접 전달할 수도 있고, 데이터 파싱을 위해서 logstash를 거쳐 ES에 저장 가능하다.
-
Q) 로그 적재 시에 json을 써서 logstash를 안써도 되지 않나요?
- 로그 시스템이 단일 서버에서만 사용한다면 가능할 수 있지만, 다양한 서버에서 로그 수집에 대한 요구사항(인덱스 구성 및 데이터 포맷)이 다를 수 있기에 일반적으로 데이터 파싱 모듈을 조합한 구성으로 설계한다.
-
Q) 네트워크 구간에 장애에 따른 데이터 유실이 있을수 있나요?
- filebeat에 경우 전송 성공한 기록 index 값을 관리하고 있기에 전송하는 Client단에는 보장 가능합니다. 쿠버네티스의 환경에서 서비스 인스턴스에 문제로 pod이 재시동이 된어도 로그 수집 경로를 Worker Node로 하여 보관 가능합니다.
- Logstash는 20개의 Fixed-Size Event 제한이 있어(메모리 대기 큐) 재시작시 지속성을 위해 외부 스트림 큐를 추가적으로 구성한다.
위 내용에 대한 것을 반영한다면 다음과 같은 아키텍처 설계를 구성할 수 있다.
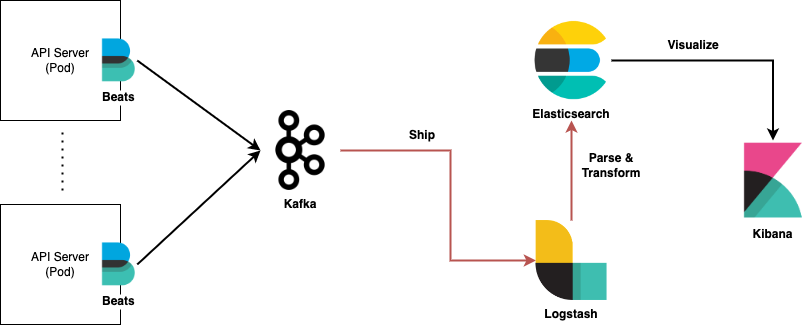
3.2 Extension
그림에서 그럼 대체 가능한 구성들은 무엇이 있고, 추가적으록 고민해야할 부분들은 언급하며 확장해보자.
(개인적인 생각) 로그 수집 시스템에 구성 모듈에 대해 분류를 나눈다면 데이터 전송을 하는 Data Shipper, 누적되는 데이터를 보관 및 유실방지를 위한 Data Stream Queue, ES의 데이터 노드 전 데이터 파싱을 위한 Data Indexer, 데이터 활용을 위한 Data Visualization으로 구분 지을 수 있다. 분류 조건으로 필요한 도구들은 대표적으로 아래와 같다.
| 분류 | 도구 |
|---|---|
| Data Shipper | Beats:Filebeat, FluentBit, … |
| Data Stream Queue | Kafka, Kinesis, RedPanda, … |
| Data Indexer | Logstash, fluentd, … |
| Data Visualization | Kibana, Grafana, … |
3.2.1 Data Shipper 비교
| 장점 | 단점 | |
|---|---|---|
| FileBeat | ES에서 제공하기에 EOS에 대한 이슈 및 문제 발생시 Communication Point가 정확함 | 모니터링이 다른 도구에 비해 빈약하며, 파일 전송 외에 필터 및 파싱에 대한 라이브러리 제약이 많음 |
| FluentBit | FluentD에 경량화로 모니터링 기능이 있으며 타 모듈보다 커뮤니티에서 더 활발히 사용하여 Issue 히스토리가 상대적으로 많음 | Enterprise Resource Planning이 없음 |
(나라면) 다음 이유로 FileBeat를 사용 할 것 같다.
- 상용 서비스 반영이니 Enterprise 레벨로 서비스 받을 수 있다는 장점
- 해외 기업이니 느리다. 정말 Deep한 이슈들이 아니면 딱히 문의 할 일이 없을 듯
- 커뮤니티 언급은 FluentBit가 많지만 사용 현황으로 보면 FileBeat가 훨씬 많으므로 소프트웨어 대한 신뢰성은 이미 검증 된것으로 간주
- 기능성 데이터 전송을 제외하고는 다른 기능을 쓸 필요 없다고 생각하며 서비스 되는 팟에서는 가장 단순하고 심플하게 사용이 맞다고 생각함
3.2.2 Data Stream Queue 비교
- https://www.softkraft.co/aws-kinesis-vs-kafka-comparison/
- https://food4ithought.com/2019/11/20/apache-kafka-vs-aws-kinesis/
| 장점 | 단점 | |
|---|---|---|
| Kafka | Kinesis보다 성능이 좋으며, 구성이 유연하며, Replication의 복잡한 설정으로 성능 제어를 세밀하게 조정 가능 | 관리를 위한 전문 인력 리소스가 필요 |
| Kinesis | 설정이 단순하며 구성도 단순하여 서비스 구성 및 운영시 learning curve가 적음 | 카프카 대비 사용룰은 1/10이며, 기능 제한이 많음 |
| RedPanda | 성능은 카프카에 몇배 이상 좋다고힘 | usecase가 많이 보이지 않아 이슈 대응이 불가능 할 수 있음 |
AWS에서 managed로 제공되는 AWS MSK가 있지만, kafka의 새로운 버전 릴리즈시 호환성 및 기능 제공에 대한 간극이 있을 수 있음. 그리고 많이 사용되지 않는다는 치명적인 단점을 지님.
키네시스와 카프카 선정하기 위하기 질문 3가지 모두 No라면 키네시스를 사용하는 것을 권고한다.
- 카프카에 대한 전문 지식을 가진 인원이 있나요?
- 1000 TPS보다 많은 처리가 필요한가요?
- 메세지가 7일 이상 지속되어야 하는가?
(나라면) 다음 이유로 Kafka를 사용 할 거 같다.
- 비용으로 보면 다변화되는 환경에서의 요구사항을 증가하고 또한 개발 서버 및 로그도 증가할 것이다. 키네시스의 경우에는 사용 시간 및 메시지 처리량에 따른 과금과 로그량이 많아질 것이기 때문에 비용이 지속적으로 증가 할 거라 생각 됨
- 사용 비율도 카프카가 압도적으로 높기 때문에 유지 보수를 위한 운영 처리에도 더 효율적이라 판단됨
3.2.3 Data Indexer 비교
- https://logz.io/blog/fluentd-logstash/
- https://www.upsolver.com/blog/comparing-apache-kafka-amazon-kinesis
| Event Routing | Plugin Ecosystem | Transport | Performance | |
|---|---|---|---|---|
| Logstash | Algorithmic statements | Centralized | Deploy With Redis for Reliability | Use more memory. Use Elastic Beats for leaft. |
| Fluentd | Tags | Decentralized | Built-in reliability but hard to configure. | Uses less memory. Use Fluent Bit and Fluentd forwarder for leafts. |
| 장점 | 단점 | |
|---|---|---|
| Logstash | ES에서 제공하는 것으로 업데이트에 따라 동일 버전사용하므로 고민이 필요 없음 | kafka나 kinesis 시스템 필요, 운영 리소스가 많아짐 |
| FluentD | 독립적인 시스템으로 생각 가능하며, Data Queue 모듈이 필요 없음 | logstash보다는 es와 궁합이 낮음 |
(나라면) 다음 이유로 FluentD를 사용 할 거 같다.
- ES 버전 업데이트가 빈번하지만 설치 후 ES를 업데이트가 필요할 때는 보안 취약점 관련해서 업데이트가 하겠지만, 실상 내부 운영으로 사용되기 때문에 이마저도 업데이트 하지 않는다.
- kafka나 kinesis도 필요 없이 운영 가능하다. (운영하는 시스템은 적을 수록 좋기 때문에)
- 실제 FluentD만으로도 충분히 상용 운영이 가능한 것을 확인하였으며, 기능상으로만 봐도 입력받고 파싱하고 출력을 내보내는 것으로 ES와 합을 맞추기 위한 기능으로 충분히 활용 가능하다.
- FluentD도 복구전략으로 파일에 쓰고 관리를 하기 때문에 예외적인 Edge Case들이 아닌 이상은 복구전략으로 문제 없다.
3.2.4 Data Visualization 비교
(나라면) Kibana는 필수/Grafana는 선택/다른 기타 등등 선택
- Grafana는 고정된 쿼리를 날려서 화면의 View를 보여주기 때문에, 인터페이스가 더 깔끔하고 보기 좋을 수는 있지만, Kibana에서처럼 키에 대한 필터를 필요할 때마다 동적으로 설정하기는 어렵기 때문에 Kibana는 필수 Grafana는 선택이라고 생각한다.
3.3 Final Architecture
3.3.1 내가 생각한 아키텍처
위에서 조사했던 내용 기반으론 내가 생각했던 아키텍처의 그림은 아래와 같다.
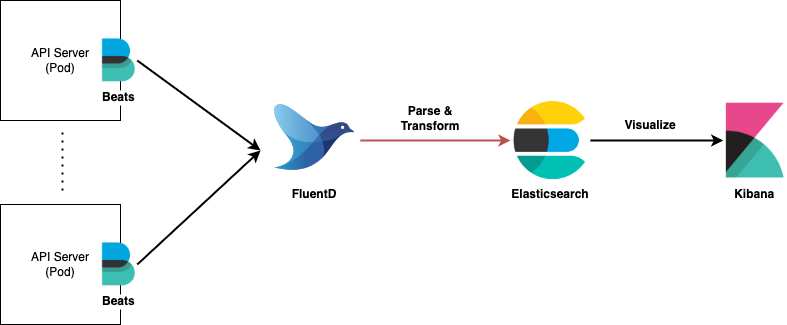
3.3.2 피드백 from 똑똑한 놈들 and Google
네이버/카카오 기타 등등에 다른 회사 지인들에게는 어떻게 쓰는지가 궁금해서 내가 생각했던거를 공유하고 피드백을 받아보았다.
그러면 AWS에 로그시스템은 어떤 기능등을 조합해서 쓰고 있는가?
- 베이스 : Kinesis/Amazon MSK-카프카 (대부분 Kinesis 사용), Amazon ES
- 그 외 : Lambda/S3
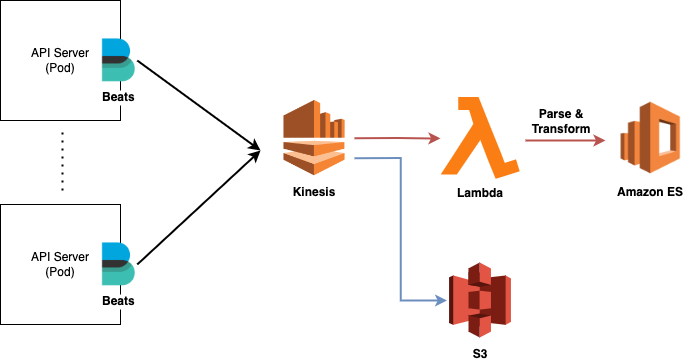
로그 데이터 전송에 경우는 어플리케이션과 분리하여 의존성을 줄이는 방법으로 파일로 로그를 쓰고, filebeat/Amazon CloudWatch/FluentBit를 사용한다. (나라면) 로그 공통 룰을 가지고 개발이 되었다면, filebeat/fluentBit를 둘중 하나 사용할 것이고, 예외적인 모듈이 한개라도 있다면 마음편히 cloudwatch를 사용할 것이다. 위의 s3를 선택한 그려놓은 이유는 필요에 따라 ES가 아닌 다른 모듈에서 로그 정보를 활용할 수 있기 때문에 확장 개념으로 보면 된다.
4 Review
고민은 엄청 많이 한거에 비해 내가 생각했던 거와 달리 결론적으로는 하나도 반영되지 않았다. 우선 많은 기업에서 클라우드의 Managed Service를 많이 사용하고 있음에도 불구하고 나의 경험부족으로 인해 신뢰성을 갖지 못했고 그로 인해 결과 도출하는데 있어 빙빙 돌아온 경향이 있었다. 또한 비용만 생각하다보니 on-premise 기반의 아키텍처로 생각이 bias되었던 부분들에 대해 부족한 점을 느낀다. 나의 지식의 부족함을 반성하고 열심히 경험쌓고 배워야겠다.